Text Processing Services
re
正则表达式
import re
# 编译
datepat = re.compile(r'\d+/\d+/\d+')
# 匹配
text1 = '11/27/2012'
if datepat.match(text1): print('yes')
# 搜索
text = 'Today is 11/27/2012. PyCon starts 3/13/2013.'
datepat.findall(text) # ['11/27/2012', '3/13/2013']
# 通常会分组匹配
datepat = re.compile(r'(\d+)/(\d+)/(\d+)')
m = datepat.match('11/27/2012')
print(m.group(0), m.group(1), m.group(2), m.group(3), m.groups())
datepat.findall(text) # [('11', '27', '2012'), ('3', '13', '2013')]
# 返回迭代
for m in datepat.finditer(text):
print(m.groups())
# 只是一次匹配/搜索操作的话可以无需先编译
re.findall(r'(\d+)/(\d+)/(\d+)', text)
# 替换
re.sub(r'(\d+)/(\d+)/(\d+)', r'\3-\1-\2', text) # 'Today is 2012-11-27. PyCon starts 2013-3-13.'
re.sub(r'(?P<month>\d+)/(?P<day>\d+)/(?P<year>\d+)', r'\g<year>-\g<month>-\g<day>', text) # 命名分组
Data Types
datetime
from datetime import datetime
a = datetime(2012, 9, 23)
# 时间转字符串
a.strftime('%Y-%m-%d')
# 字符串转时间
text = '2012-09-20'
y = datetime.strptime(text, '%Y-%m-%d')
zoneinfo (3.9+)
from datetime import datetime
from zoneinfo import ZoneInfo
# Create a datetime object without timezone
naive_dt = datetime.now()
# Add the timezone to the datetime object
aware_dt = naive_dt.replace(tzinfo=ZoneInfo('Asia/Shanghai'))
print(aware_dt)
collections
nametuple
from collections import nametuple
# namedtuple(typename, field_names)
Point = namedtuple('Point', ['x', 'y'])
p = Point(x=11, y=22)
print(p.x + p.y)
deque
from collections import deque
d = deque(["a", "b", "c"])
d.append("f") # add to the right side
d.appendleft("z") # add to the left side
e = d.pop() # pop from the right side
e = d.popleft() # pop from the left side
d = deque(maxlen=10) # deque with max length, FIFO
Counter
from collections import Counter
words = ['look', 'into', 'my', 'eyes', 'look', 'into', 'my', 'eyes']
word_counts = Counter(words)
top_three = word_counts.most_common(3)
defaultdict
自动初始化每个 key 刚开始对应的值
from collections import defaultdict
d = defaultdict(list)
d['a'].append(1)
d['a'].append(2)
d['b'].append(4)
OrderedDict
from collections import OrderedDict
d = OrderedDict()
ChainMap
先从字典 a 中找,如果找不到再在字典 b 中找
from collections import ChainMap
a = {'x': 1, 'z': 3 }
b = {'y': 2, 'z': 4 }
c = ChainMap(a,b)
Numeric and Mathematical Modules
random
import random
# 随机生成 0-1 之间的小数
random.random()
# 随机生成一个整数
random.randint(0,10)
values = [1, 2, 3, 4, 5, 6]
# 随机选取一个
random.choice(values)
# 随机采样
random.sample(values, 2)
# 打乱顺序
random.shuffle(values)
# 设定种子
random.seed(12345)
Functional Programming Modules
opertor
# lt: <
# le: <=
# eq: ==
# ne: !
# ge: >=
# gt: >
from operator import lt
lt(a, b) # a < b
# contains
from operator import contains
contains(a, b) # b in a
# getitem
from operator import getitem
getitem(a, b) # a[b]
# getattr
getattr(obj, name) # obj.name
# attrgetter
from operator import attrgetter
f = attrgetter('name') # f(b) -> b.name
# itemgetter
from operator import itemgetter
f = itemgetter(2) # f(r) -> r[2]
itertools
itertools — Functions creating iterators for efficient looping
Infinite iterators:
# count
start, step = 10, 2
for i in itertools.count(start, step):
print(i) # 10, 12, 14, ...
# cycle
s = "ABCD"
for c in itertools.cycle(s):
print(c) # A, B, C, D, A, ...
# repeat
for i in repeat(10, 3):
print(i) # 10, 10, 10
for i in repeat(10):
print(i) # 10, 10, 10, ...
Combinatoric iterators:
s1 = "abc"
s2 = "123"
# cartesian product
for c1, c2 in itertools.product(s1, s2):
print(c1, c2) # (a, 1), (a, 2), (a, 3), (b, 1), ...
# permutation
for c in itertools.permutations(s1):
print(c) # (a, b, c), (a, c, b), (b, a, c), ...
# combination
for c in itertools.combinations(s1, 2):
print(c) # (a, b), (a, c), (b, c)
# combination with replacement
for c in itertools.combinations_with_replacement(s1, 2):
print(c) # (a, a), (a, b), (a, c), (b, b), (b, c), (c, c)
Iterators terminating on the shortest input sequence:
itertools.accumulate([1,2,3,4,5]) # --> 1 3 6 10 15
itertools.chain("ABC", "DEF") # --> A B C D E F
itertools.compress("ABCDEF", [1,0,1,0,1,1]) # --> A C E F
itertools.takewhile(lambda x: x < 5, [1,4,6,4,1]) # --> 1 4
itertools.dropwhile(lambda x: x < 5, [1,4,6,4,1]) # --> 6 4 1
itertools.filterfalse(lambda x: x % 2, range(10)) # --> 0 2 4 6 8
itertools.islice("ABCDEFG", 2, None) # --> C D E F G
itertools.starmap(pow, [(2,5), (3,2), (10,3)]) # --> 32 9 1000
functools
functools — Higher-order functions and operations on callable objects
# cache
# Simple lightweight unbounded function cache.
@cache
def factorial(n):
return n * factorial(n-1) if n else 1
# Decorator to wrap a function with a memoizing callable that saves up to the maxsize most recent calls.
@lru_cache(maxsize=128)
def fib(n):
if n < 2: return n
return fib(n-1) + fib(n-2)
# cmp_to_key
# Transform an old-style comparison function to a key function.
sorted(iterable, key=cmp_to_key(locale.strcoll))
# partial
basetwo = partial(int, base=2)
basetwo('10010') # --> 18
# reduce
reduce(lambda x, y: x+y, [1, 2, 3, 4, 5]) # --> ((((1+2)+3)+4)+5)
File and Directory Access
pathlib
from pathlib import Path
p = Path('.')
# list subdirectories
[x for x in p.iterdir() if x.is_dir()]
# list Python source files
list(p.glob('**/*.py'))
# navigate directory tree
q = p / 'init.d' / 'reboot'
# check existence
q.exists()
# check is directory
q.is_dir()
glob
import glob
gif_files = glob.glob('*.gif')
tempfile
import tempfile
with tempfile.TemporaryFile() as fp:
fp.write(b'Hello world!')
fp.seek(0)
fp.read()
shutil
import shutil
# cp
shutil.copy(src, dst)
# copyfile, only copy the content of source file
shutil.copyfile(src, dst)
# chown
shutil.chown(path)
# copytree
shutil.copytree(source, destination)
# rmtree
shutil.rmtree(directory)
# make archive
archive_name = os.path.expanduser(os.path.join('~', 'myarchive'))
root_dir = os.path.expanduser(os.path.join('~', '.ssh'))
shutile.make_archive(archive_name, 'gztar', root_dir)
File Formats
configparser
配置文件
[hosts]
host = localhost
port = 27017
import configparser
config = configparser.ConfigParser()
config.read('config.ini')
HOST = config['hosts']['host']
PORT = config['hosts'].getint('port')
Generic Operating System Services
os
import os
path = "/Users/beazley/Data/data.csv"
# get basename
os.path.basename(path) # data.csv
# get dirname
os.path.dirname(path) # /Users/beazley/Data
# join path
os.path.join('tmp', 'data', os.path.basename(path)) # tmp/data/data.csv
# split file extension
os.path.splitext(path) # ('~/Data/data', '.csv')
# file/directory existence
os.path.exists('/etc/passwd')
# is file
os.path.isfile('/etc/passwd')
# is directory
os.path.isdir('/etc/passwd')
# list directory
os.listdir('/etc')
argparse
argparse - Parser for command-line options, arguments and sub-commands
params:
- action
- store (default): store and do nothing
- store_const: stores the value specified by the
constkeyword argument - store_true: if the option is specified, assign the value
True. Not specifying it impliesFalse - count: count the number of occurrences of a specific optional arguments
- nargs:
N:Narguments from the command line will be gathered together into a list?: if not present than default*: 0 - all arguments are gathered into a list+: at least one argument are gathered into a list
- default: add default value
- type: argument type
- int
- str
- choices: argument value should be one of them
- required: in default, argument starts with
-or--is treat as optional - metavar: changes the displayed name in help messages
- dest: changes the name of the attribute of the optional argument
import argparse
parser = argparse.ArgumentParser(
prog = 'ProgramName',
description = 'What the program does')
# add positional argument
parser.add_argument(
"echo",
type=str,
help="echo the string you use here")
# add optional argumenr
# argument starts with `-` or `--` is treat as optional
parser.add_argument(
"--verbosity",
help="increase output verbosity")
# with short option
parser.add_argument(
"-v",
"--verbosity",
help="increase output verbosity")
# boolean argument
parser.add_argument(
"-v",
"--verbosity",
action="store_true",
help="increase output verbosity")
# argument with choices
parser.add_argument(
"-v",
"--verbosity",
type=int,
choices=[0, 1, 2],
help="increase output verbosity")
parser.add_argument('-s', '--seed', default=0, help='the random seed',
action='store', type='int', dest='seed')
logging
Basic config
import logging
logging.basicConfig(
level=logging.DEBUG,
filename='example.log',
filemode='a',
encoding='utf-8',
format='%(asctime)s [%(levelname)s] %(pathname)s:%(lineno)d %(message)s',
datefmt='%m/%d/%Y %I:%M:%S %p'
)
logging.debug("debug")
logging.info("info")
logging.warning("warning")
logging.error("error")
logging.critical("critical")
Advanced logging
import logging
# 设置日志等级
logger = logging.getLogger(__name__) # use a module-level logger
logger.setLevel(logging.DEBUG)
# create console handler and set level to debug
ch = logging.StreamHandler()
ch.setLevel(logging.DEBUG)
logger.addHandler(ch)
logger.info("info")
同时写入文件和console
logger = logging.getLogger("my-logger")
logger.setLevel(logging.DEBUG)
# 写入文件
file_handler = logging.FileHandler("../logs/log.log", encoding='UTF-8')
file_handler.setLevel(logging.INFO)
formatter = logging.Formatter('%(asctime)s: %(levelname)s:%(message)s')
file_handler.setFormatter(formatter)
# 写入console
console_handler = logging.StreamHandler()
console_handler.setLevel(logging.DEBUG)
logger.addHandler(file_handler)
logger.addHandler(console_handler)
curses
用于控制命令行字符级别的展示
import curses
# init
stdscr = curses.initscr()
curses.noecho()
curses.cbreak()
stdscr.keypad(True)
# exit gracefully
curses.nocbreak()
stdscr.keypad(False)
curses.echo()
curses.endwin()
使用 wrapper
from curses import wrapper
def main(stdscr):
# Clear screen
stdscr.clear()
# This raises ZeroDivisionError when i == 10.
for i in range(0, 11):
v = i-10
stdscr.addstr(i, 0, '10 divided by {} is {}'.format(v, 10/v))
stdscr.refresh()
stdscr.getkey()
wrapper(main)
Concurrent Execution
threading
# Code to execute in an independent thread
import time
def countdown(n):
while n > 0:
print('T-minus', n)
n -= 1
time.sleep(5)
# Create and launch a thread
from threading import Thread
t = Thread(target=countdown, args=(10,))
t.start() # 运行线程
# 合并到当前线程,等待其结束
t.join()
给共享数据加锁
import threading
class SharedCounter:
'''
A counter object that can be shared by multiple threads.
'''
def __init__(self, initial_value = 0):
self._value = initial_value
self._value_lock = threading.Lock()
def incr(self,delta=1):
'''
Increment the counter with locking
'''
with self._value_lock:
self._value += delta
def decr(self,delta=1):
'''
Decrement the counter with locking
'''
with self._value_lock:
self._value -= delta
标准包内没有读写锁,如果需要可以使用第三方包 – readerwriterlock
# !pip install readerwriterlock
from readerwriterlock import rwlock
a = rwlock.RWLockFairD()
with a.gen_rlock():
# Read stuff
with a.gen_wlock():
# Write stuff
multiprocessing
创建子进程
from multiprocessing import Process
import os
def say_hello(name):
print(f'PID {os.getpid()}: hello {name}.')
if __name__ == '__main__':
p = Process(target=say_hello, args=('Tom', )) # 创建子进程对象
p.start() # 运行子进程
p.join() # 等待子进程返回
进程池
from multiprocessing import Pool
def fibonacci(x):
if x <= 1: return x
if x >= 40: raise ValueError
return fibonacci(x - 2) + fibonacci(x - 1)
if __name__ == '__main__':
# takes about 5~6 seconds
with Pool(3) as p:
print(p.map(fibonacci, [35] * 3))
# takes about 20 seconds
with Pool(3) as p:
print(p.map(fibonacci, [35] * 10))
进程间通信
Queue
from multiprocessing import Process, Queue
import os, time, random
# 写数据进程执行的代码:
def write(q):
print('Process to write: %s' % os.getpid())
for value in ['A', 'B', 'C']:
print('Put %s to queue...' % value)
q.put(value)
time.sleep(random.random())
# 读数据进程执行的代码:
def read(q):
print('Process to read: %s' % os.getpid())
while True:
value = q.get(True)
print('Get %s from queue.' % value)
if __name__=='__main__':
# 父进程创建Queue,并传给各个子进程:
q = Queue()
pw = Process(target=write, args=(q,))
pr = Process(target=read, args=(q,))
# 启动子进程pw,写入:
pw.start()
# 启动子进程pr,读取:
pr.start()
# 等待pw结束:
pw.join()
# pr进程里是死循环,无法等待其结束,只能强行终止:
pr.terminate()
# 使用管道
Pipe
from multiprocessing import Process, Pipe
def f(conn):
conn.send([42, None, 'hello'])
conn.close()
if __name__ == '__main__':
parent_conn, child_conn = Pipe() # Pipe()返回一对可以双向通信的连接
p = Process(target=f, args=(child_conn,))
p.start()
print(parent_conn.recv()) # prints "[42, None, 'hello']"
p.join()
conccurent.futures
# 多线程
from concurrent.futures import ThreadPoolExecutor, as_completed
import time
def wait(n):
time.sleep(n)
print(f"Waited {n} seconds.")
def fibonacci(x):
if x <= 1: return x
if x >= 40: raise ValueError
return fibonacci(x - 2) + fibonacci(x - 1)
with ThreadPoolExecutor(max_workers=workers) as pool:
future = pool.submit(wait, [1] * 10) # submit后子进程开始运行
# 查看子进程是否在运行
future.running()
# 等待结果返回
future.result()
# future.result()回阻塞主进程,如果不想阻塞,可以使用回调函数
def when_done(r):
print('Got:', r.result())
with ThreadPoolExecutor() as pool:
future = pool.submit(wait, 1)
future.add_done_callback(when_done)
# as_completed函数返回一个包含指定的 Future 实例的迭代器,这些实例会在完成时被 yield 出来
with ThreadPoolExecutor() as pool:
futures = [pool.submit(wait, random.randint(1, 5)) for _ in range(10)]
for future in as_completed(futures):
print(future.result())
# map写法
# max_workers默认值为 min(32, cpu核数+4),3.7版本之前为 5*cpu核数
# 当有一个进程报错时,生成器退出,如果需要捕获异常建议用submit
# 可以指定任务超时时间timeout
# chunksize默认为1,当任务数量很大,执行时间较短时,可以将chunksize调大,每次分配多个任务给每个子进程
with ThreadPoolExecutor(max_workers=workers, timeout=60, chunksize=100) as pool:
result = pool.map(wait, [1] * n)
return result
# 多进程
from concurrent.futures import ProcessPoolExecutor
# submit写法
# max_workers默认值为cpu核数
with ProcessPoolExecutor(max_workers=workers) as pool:
futures = [pool.submit(fibonacci, 30) for _ in range(n)]
return [res for res in as_completed(futures)]
# map写法
with ProcessPoolExecutor(max_workers=workers) as pool:
result = pool.map(fibonacci, [30] * n)
return result
subprocess
# doesn't capture output
subprocess.run(["ls", "-l"])
# capture output
p = subprocess.run(["ls", "-l", "/dev/null"], capture_output=True)
print(p.stdout)
# run command string
subprocess.run("ls -l", shell=True)
# or
import shlex
subprocess.run(shlex.split("ls -la"))
# raise error if command fails
subprocess.run(["ls", "noexists"], check=True)
# pipeline
p1 = subprocess.Popen(["dmesg"], stdout=subprocess.PIPE)
p2 = subprocess.Popen(["grep", "hda"], stdin=p1.stdout, stdout=subprocess.PIPE)
p1.stdout.close() # Allow p1 to receive a SIGPIPE if p2 exits.
output = p2.communicate()[0]
# or (input trusted)
output = subprocess.check_output("dmesg | grep hda", shell=True)
Networking and Interprocess Communication
socket
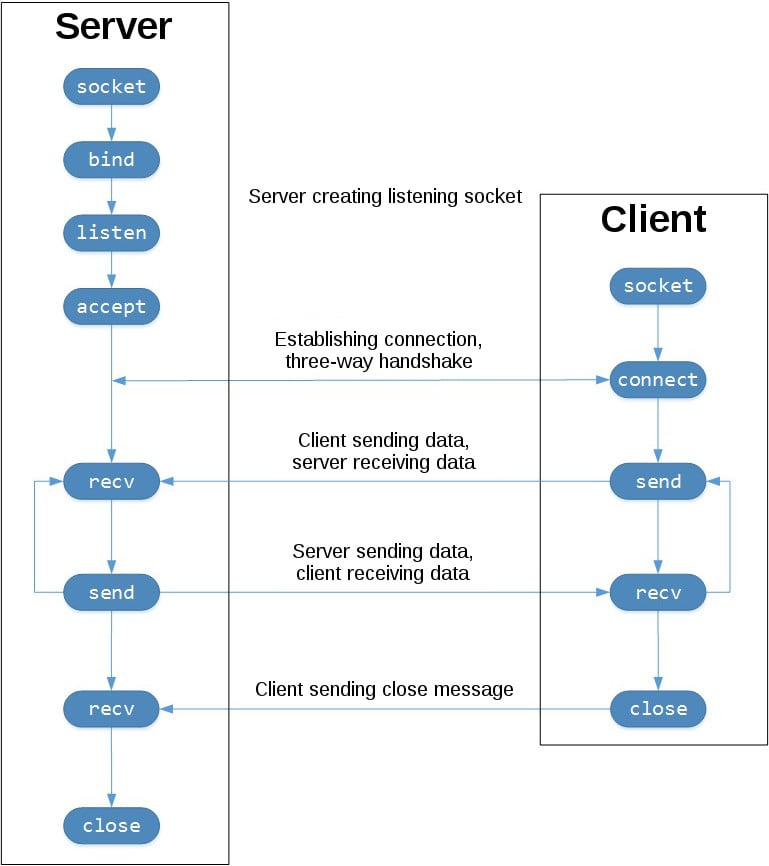
server
import socket
HELLO_MSG = "Hello world"
if __name__ == "__main__":
# Server socket doesn’t send any data.
# It doesn’t receive any data.
# It just produces “client” sockets.
server = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
print(socket.gethostname())
server.bind(('', 12358))
server.listen(1)
while True:
conn, addr = server.accept()
try:
conn.send(HELLO_MSG.encode())
while True:
print("waiting...")
data = conn.recv(1028)
print(f"receive: {data}")
if len(data) == 0:
break
conn.send(data.upper())
except:
raise
finally:
conn.close()
client
import socket
if __name__ == "__main__":
conn = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
try:
conn.connect(('192.168.3.3', 12358))
print("connected")
while True:
data = conn.recv(1024)
print(data.decode())
msg = input()
conn.send(msg.encode())
except:
raise
finally:
conn.close()
asyncio
用async定义异步函数
import asyncio
async def do_something():
l = []
for i in range(10000):
l.append(i ** 3)
print(len(l))
print("finish.")
异步函数要用await来调用
# 只会返回一个coroutine对象,并不会执行函数
def main():
do_something()
# 要用run来执行
asyncio.run(do_something())
# 或者在别的异步函数中调用
async def main():
await do_something() # 异步函数通过await来调用,await只能放在async函数内
asyncio.run(main())
或者通过旧式的API运行
loop = asyncio.get_event_loop()
loop.run_until_complete(main())
顺序调用异步函数并不能同时执行
import asyncio
import time
async def do_something_cost_time(something, cost_time):
await asyncio.sleep(cost_time)
print(f"{something} is done at {time.strftime('%X')}.")
async def main():
print(f"started at {time.strftime('%X')}")
await do_something_cost_time("WashClothes", 2)
await do_something_cost_time("WatchTV", 5) # 会等上一行执行完了再执行
print(f"finished at {time.strftime('%X')}")
asyncio.run(main())
如果需要同时(concurrently)执行多个异步函数,需要将异步函数定义为task
async def main():
print(f"started at {time.strftime('%X')}")
task1 = asyncio.create_task(do_something_cost_time("WashClothes", 2))
task2 = asyncio.create_task(do_something_cost_time("WatchTV", 5))
task3 = asyncio.create_task(do_something_cost_time("FeedBaby", 3))
# await除了可以调用异步函数,也可以调用task
await task1 # 启动所有task,同时执行
# print(1) # print when task1 finishes
await task2
# print(2) # print when task1 and task2 finish
await task3
# print(3) # print when task1, task2 and task3 finish
# 只要await第一个task所有tasks就会同时开始执行,但是await后面的语句会等它前面所有的await完成才会执行
print(f"finished at {time.strftime('%X')}")
asyncio.run(main())
用asyncio.gather的方式同时定义并执行tasks
async def main():
await asyncio.gather(
do_something_cost_time("WashClothes", 2),
do_something_cost_time("WatchTV", 5),
do_something_cost_time("FeedBaby", 3),
)
asyncio.run(main())
或者通过旧式的API运行
loop = asyncio.get_event_loop()
tasks = [
do_something_cost_time("WashClothes", 2),
do_something_cost_time("WatchTV", 5),
do_something_cost_time("FeedBaby", 3),
]
loop.run_until_complete(asyncio.wait(tasks))
loop.close()
Event Loop
核心是一个 Queue,在一个循环中不断 pop 下一个 ready 的 callback 来执行
Usage:
# create and access a new asyncio event loop
loop = asyncio.new_event_loop()
print(loop)
# output: <_UnixSelectorEventLoop running=False closed=False debug=False>
# access he running event loop
loop = asyncio.get_running_loop()
# to execute a task (blocking)
loop.run_until_complete(asyncio.sleep(2))
# schedule a task (non blocking)
task = loop.create_task(asyncio.sleep(2))
# close the event loop
loop.close()
# stop the event loop
loop.stop()
# run forever until stopped
loop.run_forever()
# check loop status
loop.is_running()
loop.is_closed()
Run event loop in Process/Thread Executor
# create an executor
with ThreadPoolExecutor() as exe:
# execute a function in event loop using executor
loop.run_in_executor(exe, task)
Internet Data Handling
json
Import
import json
data = {
'name' : 'ACME',
'shares' : 100,
'price' : 542.23
}
Working with string
json_str = json.dumps(data)
data = json.loads(json_str)
Working with file
with open('data.json', 'w') as f:
json.dump(data, f)
with open('data.json', 'r') as f:
data = json.load(f)
from email.mime.text import MIMEText
import ssl
import smtplib
mail = MIMEText(msg)
mail['Subject'] = 'Hello'
mail['From'] = 'myemail@qq.com'
mail['To'] = 'destination@qq.com'
context = ssl.create_default_context()
try:
server = smtplib.SMTP('smtp.qq.com', 587)
server.ehlo() # Can be omitted
server.starttls(context=context) # Secure the connection
server.ehlo() # Can be omitted
server.login('myemail@qq.com', '***)
server.sendmail('myemail@qq.com', 'destination@qq.com', mail.as_string())
except Exception as e:
print(e)
sent = False
finally:
server.quit()
Importing Modules
importlib
for module_name in os.listdir(os.path.dirname(__file__)):
if module_name != "__init__.py" and module_name.endswith(".py"):
module_name = Path(module_name).stem
module = import_module(".".join([__package__, module_name]))